What was built
Multi-Agent Architecture
9 specialized agents with unique, isolated roles — each one replaceable without breaking the system. One central orchestrator coordinates them all.
Persistent Memory
The system remembers past conversations, consolidates them over time, and retrieves the most relevant context automatically — no manual input required.
Hybrid RAG Pipeline
Combines text search, vector search, and code dependency analysis to give the AI precise, hallucination-resistant answers from its own knowledge base.
Self-Auditing Code
A dedicated agent continuously scans the codebase using static analysis (AST) to catch contract violations and data integrity issues in real time.
Zero-Boilerplate Infrastructure
Metaprogramming automatically injects logging, monitoring, and statistics into every agent at creation — no repetitive setup code.
Real-Time Observability
A live dashboard (Prompt Viewer) shows exactly what context the AI receives before generating each response — essential for debugging complex pipelines.
Architectural principles
Cognitive pipeline
From a user message to a validated, memory-backed response — every step is audited, scored for relevance, and logged before the AI generates a single word.
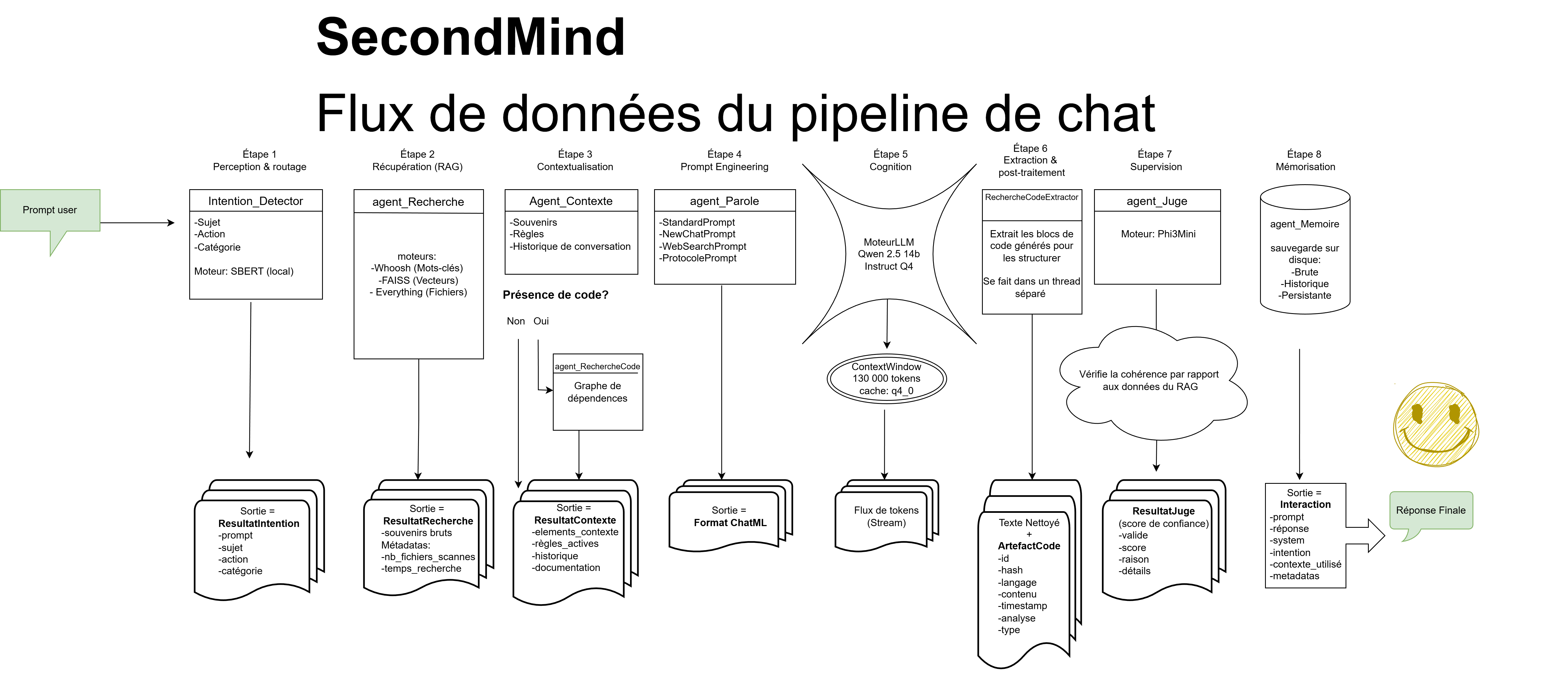
Data pipeline — from user input to memory-backed LLM response.
Hardware & performance
The entire system runs on consumer hardware. Optimized to handle a 130,000-token context window — roughly 200 pages of text — on a single GPU without running out of memory.
Context Window
130,000 tokens
Main Model
Qwen 2.5 — 14B
Judge Model
Phi-3 Mini — 3B
Intent Router
SBERT (~10ms)
GPU
RTX 3090 — 24 GB
Cache Optimization
Q4 / Q8 KV Cache
Interface
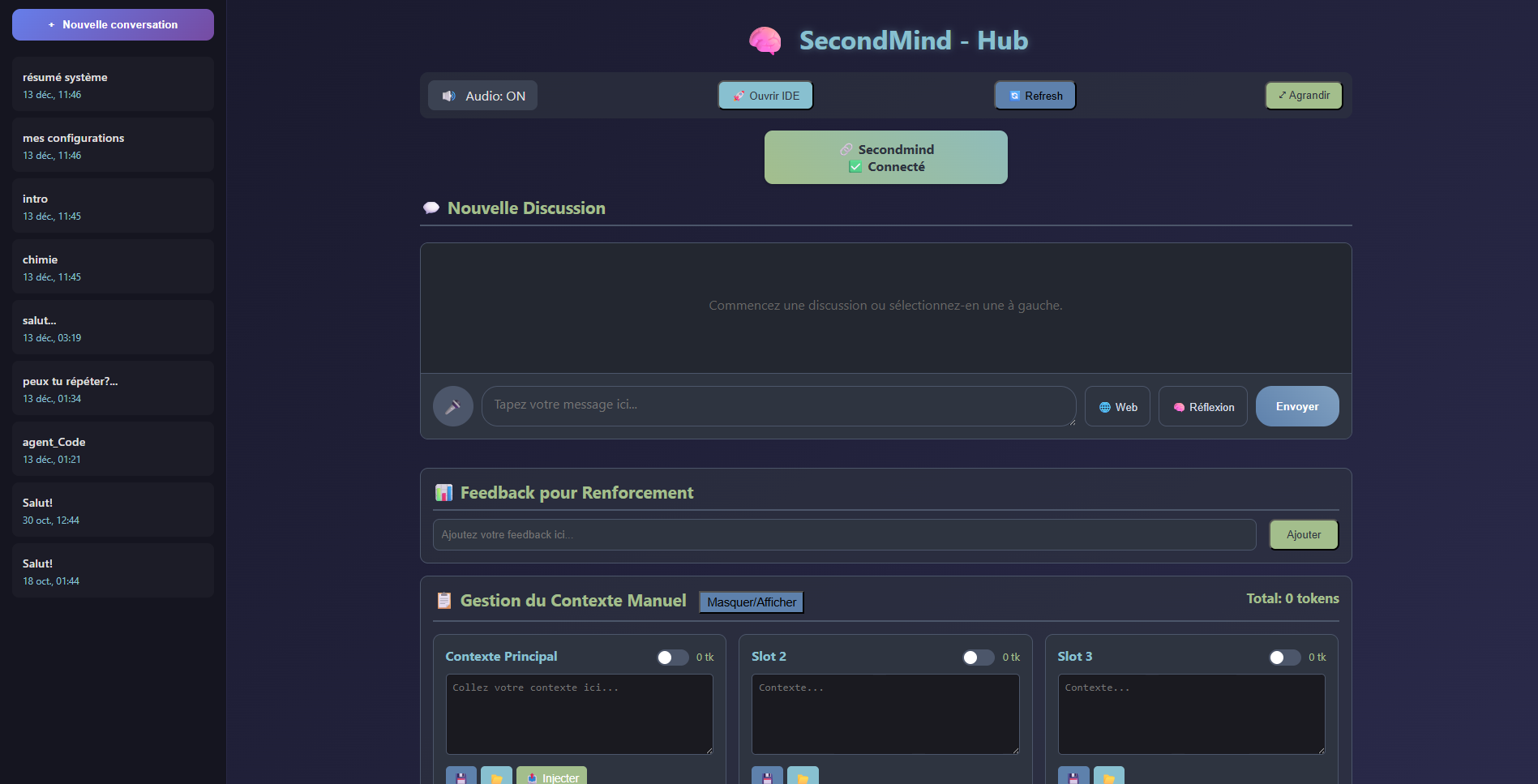
Chat interface — context slots, live token counter, and reflexive feedback controls.